
wut0n9
1/14/2019 - 11:16 AM
文本纠错
文本纠错
《Chinese Spelling Error Detection and Correction Based on Language Model, Pronunciation, and Shape》[1, Yu, 2013] 论文提供了一种准确较高、召回较低的纠错方法。
- Character级别 n-gram language model。
- 拼音和字形召回候选
- 词典过滤掉部分无效候选
- 取最高语言模型打分
- 高于既定阈值则认为是替换候选
系统流程图:
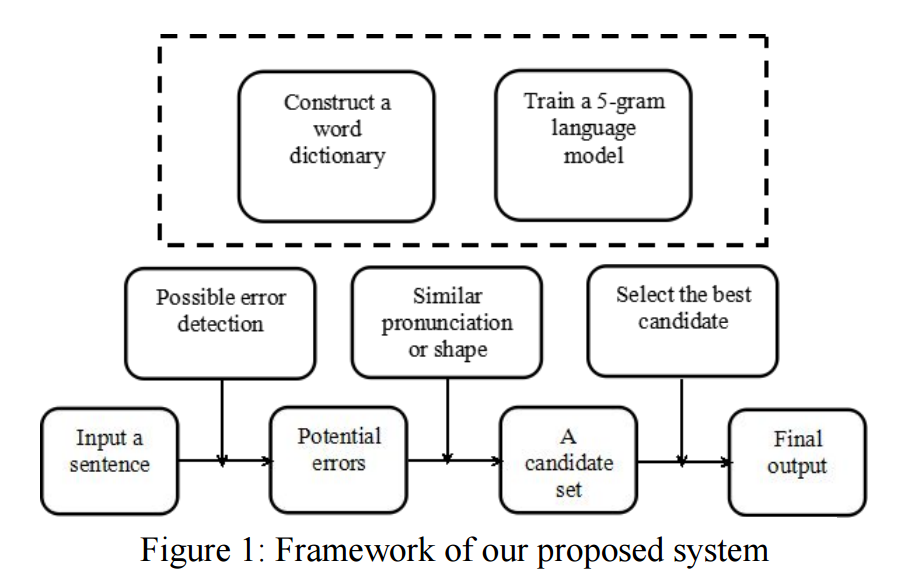
各步骤展开,具体简述如下:
- 判断何处有输入错误,两种方式:
- a. 使用正向反向的character级别的ngram语言模型,对每个位置进行打分,得分低的地方标记为待纠错片段。
- b. 切词切出独立的字符。
- 这里的ngram语言模型为5-gram,为了避免过多召回,阈值设定较为严苛。通过语言模型判断出的可疑位置将与上下文组合进行词典查词。
- 召回:上一步词典过滤出的最终可疑词进行同音字和形近字的召回。召回候选与前后近邻组合为词进行词典查词过滤出有效候选。
- 打分:候选中语言模型最高分,且得分大于阈值,则胜出。
source:水滴石穿
- 使用语言模型计算句子或序列的合理性
- bigram, trigram, 4-gram 结合,并对每个字的分数求平均以平滑每个字的得分
- 根据Median Absolute Deviation算出outlier分数,并结合jieba分词结果确定需要修改的范围
- 根据形近字、音近字构成的混淆集合列出候选字,并对需要修改的范围逐字改正
- 句子中的错误会使分词结果更加细碎,结合替换字之后的分词结果确定需要改正的字
- 探测句末语气词,如有错误直接改正
source:ccheng